
In questa pagina ci occuperemo della fonetica di tipo segmentale.
Nella nostra lingua italiana, tralasciando i dialetti e le cadenze regionali, le vocali si suddividono in:
| APERTE
SEMIAPERTE SEMICHIUSE CHIUSE |
POSTERIORI ANTERIORI |
LABIALIZZATE
NON LABIALIZZATE |
secondo questa struttura:
| VOCALI |
POSIZIONE |
CODICE IPA |
||
|
i |
ANTERIORE |
NON LABIALIZZATA |
CHIUSA |
i
|
|
é |
ANTERIORE |
NON LABIALIZZATA |
SEMICHIUSA |
e
|
| è |
ANTERIORE |
NON LABIALIZZATA |
SEMIAPERTA |
ɛ
|
| a |
ANTERIORE |
NON LABIALIZZATA |
APERTA |
a |
| ò |
POSTERIORE |
LABIALIZZATA |
SEMIAPERTA |
ɔ
|
| ó |
POSTERIORE |
LABIALIZZATA |
SEMICHIUSA |
o
|
| u |
POSTERIORE |
LABIALIZZATA |
CHIUSA |
u
|
Sostanzialmente la produzione vocalica viene determinata dal
rapporto tra alcuni parametri:
|
LINGUA |
LABBRA
|
MASCELLARE
INFERIORE
|
|
posizionamento variabile all'interno del cavo orale |
tensione
protusione arrotondamento |
posizionamento
variabile
|
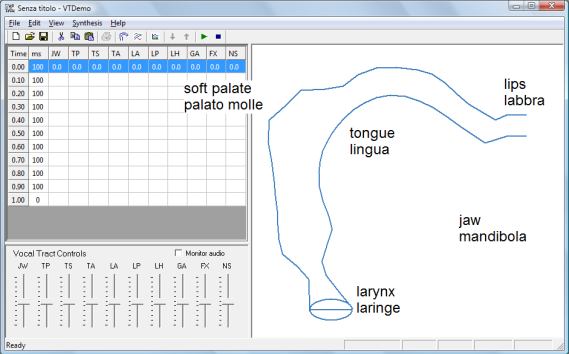
Nel prossimo video ho utilizzato l'applicazione VTDemo (purtroppo
solo per Win), grazie alla quale possiamo avere conferma di quanto
sopra asserito; le posizioni variabili di lingua e labbra sono
sufficienti per determinare la classificazione vocalica. I
parametri su cui possiamo agire utilizzando questo software sono
molti e basati su modelli articolatori di Johan Liljencrantz,
Gunnar Fant e Shinji Maeda, rinomati studiosi di linguistica
e fonetica. Ciò può avvenire tanto in real time
quanto programmando nel tempo una sequenza di azioni.
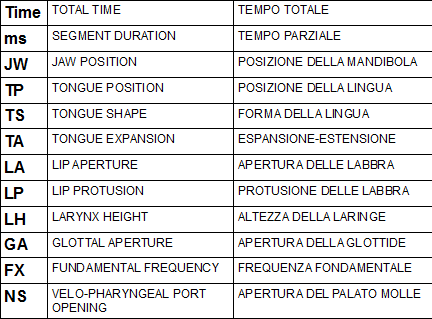
Qui sotto la schermata principale (ho aggiunto io alcuni termini)
e l’elenco dei parametri su cui possiamo intervenire per le
modifiche, sia in TIME EDITING sia in VOCAL TRACT CONTROLS:
 |
|
 |
Ecco VTDemo in azione:
Tecnica di analisi e interpretazione:
FFT Fast Fourier Transform: trasformata veloce di Fourier
versione ottimizzata della
DFT Discrete Fourier Transform: trasformata discreta di Fourier
FFT => scomposizione di un segnale in una serie di suoni sinusoidali, ciascuno con propria frequenza, ampiezza e fase
Nel
nostro caso un suono vocale risulterà perciò come somma algebrica
di una serie di componenti sinusoidali
Tra le varie rappresentazioni grafico/matematiche del segnale vocale, le più efficaci sono:
SONAGRAM - SONOGRAM

In ascissa abbiamo il tempo, in ordinata la frequenza, e le linee orizzontali rappresentano le componenti armoniche. In realtà, in questo tipo di rappresentazione bi-dimensionale interviene un terzo parametro, il colore, le cui differenti gradazioni sono in relazione con diverse intensità delle componenti armoniche. Ormai la maggior parte dei software di audio analisi offre dei colormap predefiniti e spesso anche editabili a piacimento.
POWER SPECTRUM - ANALISI DELLA FREQUENZA

In ascissa abbiamo la frequenza e in ordinata abbiamo l'intensità.
I picchi verticali rappresentano le componenti armoniche.
Nell'immagine abbiamo uno spaccato istantaneo di un evento sonoro
in un momento X del suo svolgimento acustico. Notiamo a sinistra
alcune componenti armoniche con una certa intensità, destinata a
scemare in quelle successive.
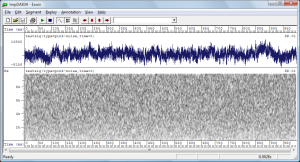
Nell'immagine sopra abbiamo la rappresentazione di
1 secondo di rumore;
nella parte superiore abbiamo la forma d'onda, in quella inferiore
un'immagine confusionale, il suo sonagramma.
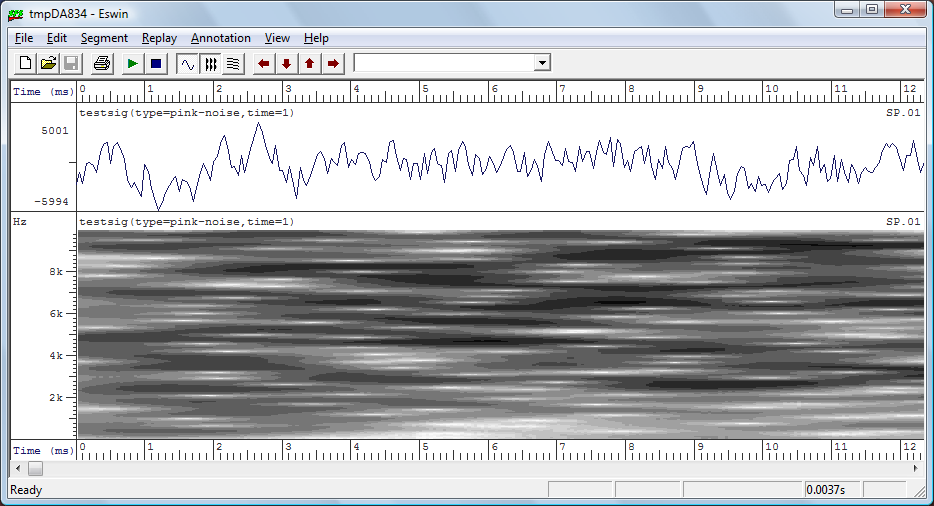
Qui
abbiamo la medesima forma d'onda con "zoom in" a 12 millisecondi;
il sonagramma risulta ancora complessivamente irregolare.
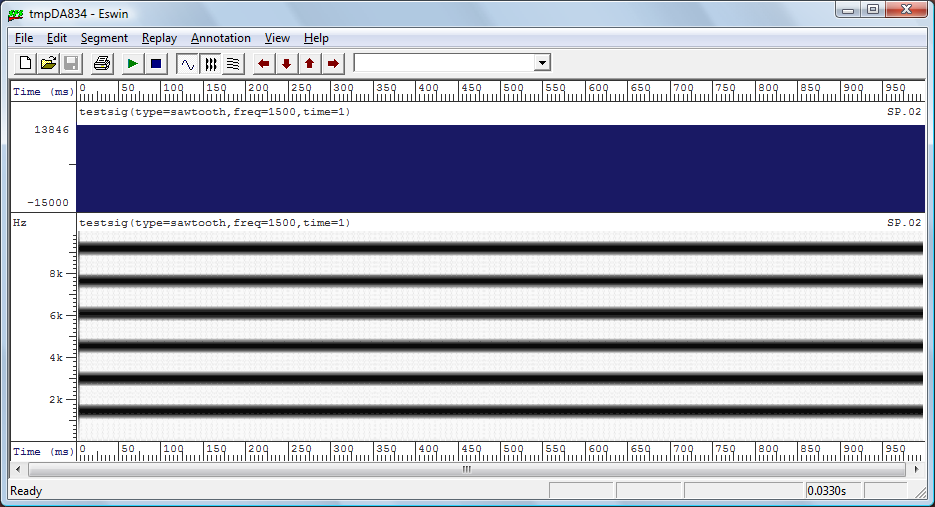
Cambiamo
segnale audio, qui abbiamo una forma d'onda a dente di
sega, 1 secondo a 1500 Hertz (Hz o CPS, cicli per
secondo);
ciò che notiamo subito è la forma d'onda graficamente compressa -
1500 cicli in pochi centimetri - rappresentata da una banda blu
uniforme.
Zoomando l'immagine...
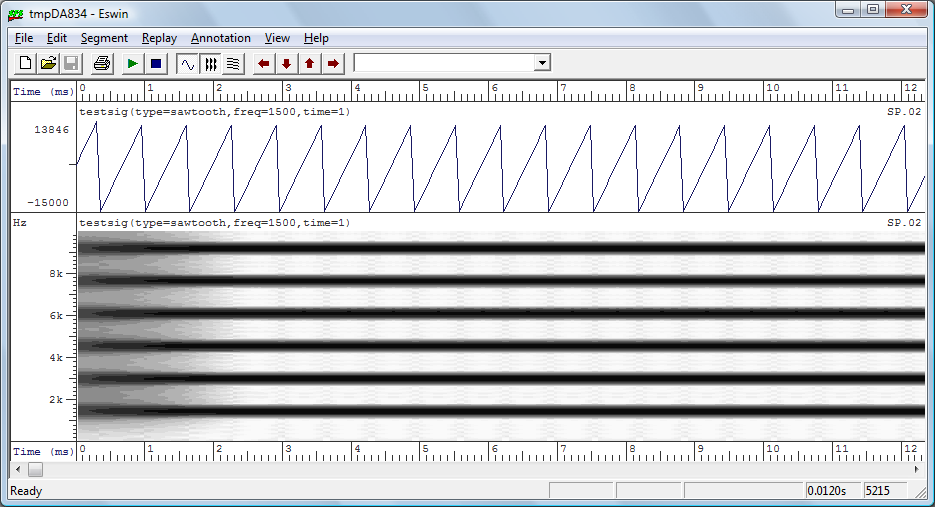
possiamo
notare distintamente i cicli, creste e gole/avvallamenti (guarda
sotto), se ne possono contare 15 in 10 millisecondi, infatti
1500 Hz : 1 sec = 15 Hz : 10 msec
e il sonogramma presenta una serie di bande orizzontali ben
distinte, le componenti armoniche, parallele ed equidistanti l'una
dall'altra.
|
|
|
Dato ciò possiamo capire che:
per cui:
Aspetto particolare nella serie degli armonici è la relazione tra gli intervalli di ottava; proviamo a considerare un segnale audio a 100 Hz, esso sarà costituito da:
h1 =
100 Hz
h2 =
200 Hz
h3 =
300 Hz
h4 =
400 Hz
e così via...
In questo caso la frequenza di ciascun componente armonico hn sarà un multiplo della frequenza fondamentale F0, ovvero hn = (h1)n oppure hn = (F0)n; il rapporto di ottava tra le componenti armoniche si basa sul rapporto 2:1 tra un armonico hn e un suo antecedente:
h1
= 100 Hz
h2 = 200
Hz
h4 = 400
Hz
h8 = 800 Hz
h16 = 1600
Hz
h32 = 3200
Hz
e via a seguire ...
Altro esempio nell'immagine successiva:
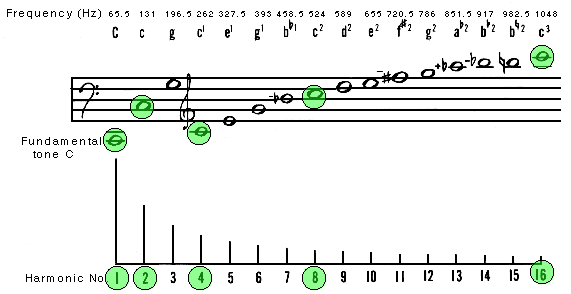
E ancora, gli armonici in posizione pari sono multipli ottava di un rispettivo antecedente, il 2° è multiplo ottava del 1°, il 4° del 2°, il 6° del 3°, l'8° del 4°, il 10° del 5°, ... (rapporto 2:1), mentre gli armonici dispari introducono una frequenza corrispondente a una nuova nota, non ancora apparsa nella serie.
Altra particolarità; con diapason a 440 Hz consideriamo alcuni intervalli, ad esempio di 5°, tralasciando i decimali e approssimando:

mentre la differenza in Hz tra le due frequenze che costituiscono ciascun intervallo varia nei tre esempi, notiamo come il loro rapporto rimanga invece costante; da ciò si evince che per calcolare/confrontare gli intervalli il nostro sistema di codifica della percezione acustica considera il
tra le frequenze, non le frequenze a sè stanti. Così noi
percepiamo sempre lo stesso intervallo - a partire da qualsiasi
frequenza - solo se il rapporto tra le frequenze è costante,
in questo caso 3:2.
